¿ADN
o proteínas?
Los cromosomas, al igual que todos los otros componentes de
una célula viva, están formados por átomos organizados en moléculas. Ciertos
científicos pensaron que resultaba imposible comprender la complejidad de la
herencia basándose en la estructura de compuestos químicos "sin vida". Los
primeros análisis químicos del material hereditario mostraron que el cromosoma
eucariótico está formado por ácido desoxirribonucleico (ADN) y proteínas,
en cantidades aproximadamente iguales. Por consiguiente, ambos eran candidatos
para desempeñar el papel de material genético. Las proteínas parecían ser la
elección más probable por su mayor complejidad química. Las proteínas son
polímeros de aminoácidos, de los que existen 20 tipos diferentes en las células
vivas. Por contraste, el DNA es un polímero formado sólo por cuatro tipos
diferentes de nucleótidos.
Hasta la década de 1940, muchos biólogos teóricos se
apresuraron en señalar que los aminoácidos, cuyo número era tan llamativamente
cercano al número de letras de nuestro alfabeto, podían disponerse en una
variedad de formas distintas; creían que los aminoácidos constituían un
lenguaje, "el lenguaje de la vida", que deletreaba las instrucciones para las
numerosas actividades de la célula. Muchos investigadores prominentes, en
particular los que habían estudiado proteínas, creían que los genes mismos eran
proteínas. Pensaban que los cromosomas contenían modelos maestros de todas las
proteínas que podría necesitar la célula y que las enzimas y otras proteínas
activas durante la vida celular eran copiadas de estos modelos maestros. Esta
era una hipótesis lógica pero, según se vio posteriormente, errónea.
Los aminoácidos contienen un grupo amino (-NH2) y
un grupo carboxilo (-COOH) unidos a un átomo de carbono central. Un átomo de
hidrógeno y un grupo lateral están también unidos al mismo átomo de carbono.
Esta estructura básica es idéntica en todos los aminoácidos. La "R" indica el
grupo lateral, que es diferente en cada tipo de aminoácido. Los veinte
aminoácidos que pueden constituir las proteínas. Como puede verse, la estructura
esencial es la misma en las veinte moléculas, pero los grupos laterales
difieren. Estos grupos pueden ser no polares (sin diferencia de carga entre
distintas zonas del grupo), polares pero con cargas balanceadas de modo tal que
el grupo lateral en conjunto es neutro, o cargados, negativa o positivamente.
Los grupos laterales no polares no son solubles en agua, mientras que los grupos
laterales polares y cargados son solubles en agua.
|
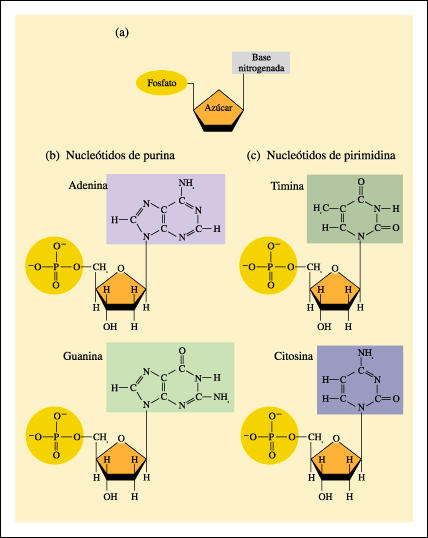
a) Un nucleótido está constituido por tres componentes
diferentes: una base nitrogenada, un azúcar de cinco carbonos
y un grupo fosfato. b) Los cuatro tipos de nucleótidos que se encuentran
en el DNA. Cada nucleótido consiste en una de las cuatro bases
nitrogenadas posibles, un azúcar desoxirribosa y un grupo fosfato. |
 |
El DNA, el Código Genético y su
traducción
Por muchos años, la genética clásica se dedicó a estudiar los
mecanismos de la herencia, a dilucidar la manera en que las unidades
hereditarias pasan de una generación a la siguiente y a investigar cómo los
cambios en el material hereditario se expresan en los organismos individuales.
En la década de 1930, surgieron nuevas preguntas y los genetistas comenzaron a
explorar la naturaleza del gen, su estructura, composición y propiedades.
A comienzos de la década de 1940, ya no quedaban dudas sobre
la existencia de los genes ni sobre el hecho de que estuviesen en los
cromosomas. Ciertos científicos pensaban que si se llegaba a comprender la
estructura química de los cromosomas, entonces se podría llegar a comprender su
funcionamiento como portadores de la información genética. Los primeros análisis
químicos del material hereditario mostraron que el cromosoma eucariótico está
formado por ácido desoxirribonucleico (DNA) y proteínas, en cantidades
aproximadamente iguales. Antes de conocerse cuál era, tanto el DNA como las
proteínas eran buenos candidatos para ser la molécula portadora del material
genético. Esta línea de pensamiento marcó el comienzo de la vasta gama de
investigaciones que conocemos como genética molecular.
Ya avanzada la década de 1940, algunos investigadores
llegaron a una conclusión importante: el material hereditario podía ser el ácido
desoxirribonucleico (DNA).
En 1953, los científicos Watson y Crick reunieron datos
provenientes de diferentes estudios acerca del DNA. Sobre el análisis de esos
datos, Watson y Crick postularon un modelo para la estructura del DNA y fueron
capaces de deducir que el DNA es una doble hélice, entrelazada y sumamente
larga.
Una propiedad esencial del material genético es su capacidad
para hacer copias exactas de sí mismo. Watson y Crick supusieron que debía haber
alguna forma en que las moléculas de DNA pudiesen replicarse rápidamente y con
gran precisión, de modo que les fuese posible pasar copias fieles de célula a
célula y del progenitor a la descendencia, generación tras generación. Watson y
Crick propusieron un mecanismo para la replicación del DNA. Dedujeron que la
molécula de DNA se replica mediante un proceso semiconservativo en el que se
conserva la mitad de la molécula.
El modelo de Watson y Crick mostró de qué manera se podía
almacenar la información en la molécula de DNA.
A medida que avanzaban los años, en la década de 1940, los
biólogos comenzaron a notar que todas las actividades bioquímicas de la célula
viva dependen de ciertas proteínas diferentes y específicas, las enzimas y que
incluso la síntesis de enzimas depende de enzimas. Más aun, se estaba haciendo
claro que la especificidad de las diferentes enzimas es el resultado de la
estructura primaria de estas proteínas, es decir, de la secuencia lineal de
aminoácidos que forman la molécula y que, a su vez, determina mayormente su
estructura tridimensional. Se comprobó que las proteínas tenían una
participación fundamental en todos los procesos bioquímicos y esto promovió la
realización de estudios posteriores. Así, se demostró cuál es la relación existe
una relación entre genes y proteínas.
Como resultado de los estudios realizados para dilucidar la
relación entre DNA y proteínas hubo un acuerdo general en que la molécula de DNA
contiene instrucciones codificadas para las estructuras y las funciones
biológicas. Además, estas instrucciones son llevadas a cabo por las proteínas,
que también contienen un "lenguaje" biológico altamente específico. La cuestión
entonces se convirtió en un problema de traducción: ¿de qué manera el orden de
los nucleótidos en el DNA especifica la secuencia de aminoácidos en una molécula
de proteína? La búsqueda de la respuesta a esta pregunta llevó a una importante
conclusión: el ácido ribonucleico (RNA) era un buen candidato para desempeñar un
papel en la traducción de la información.
Como se descubrió posteriormente, no hay una, sino tres
clases de RNA que desempeñan funciones distintas como intermediarios en los
pasos que llevan del DNA a las proteínas: el RNA mensajero (mRNA), el RNA de
transferencia (tRNa) y el RNA ribosomal (rRNA).
Los científicos de muchas disciplinas se abocaron a
investigaciones dedicadas a estudiar la correspondencia entre el lenguaje de
nucleótidos en el DNA y el lenguaje de aminoácidos en las proteínas. Así,
finalmente se dilucidó el código genético. Una vez conocido el código genético,
se pudo centrar la atención en el problema de cómo la información codificada en
el DNA y transcripta en el mRNA es luego traducida a la secuencia específica de
aminoácidos en las proteínas. De esta manera, se establecieron los principios
básicos de la síntesis de proteínas. Estos principios son los mismos en las
células eucarióticas y en las procarióticas, pero hay algunas diferencias en la
localización de los procesos, además de algunos detalles.
Hace casi 90 años, De Vries definió la mutación en función de
características que aparecen en el fenotipo. A la luz del conocimiento actual,
la definición de mutación es algo diferente a la propuesta por de Vries: una
mutación es un cambio en la secuencia o número de nucleótidos en el DNA de una
célula.
En las décadas transcurridas desde que fue descifrado el
código genético, se han examinado el DNA y las proteínas de muchos organismos.
La evidencia actual es abrumadora: el código genético es el mismo para
virtualmente todos los seres vivos, es decir, es universal. Sin embargo,
recientemente se han encontrado algunas pocas excepciones interesantes. El
origen del código es el problema de la biología evolutiva que nos deja más
perplejos. La maquinaria de traducción es tan compleja, tan universal y tan
esencial que es difícil imaginar cómo pudo haber surgido o cómo la vida puede
haber existido sin ella.
Código genético
El código genético consiste en el sistema de tripletes
denucleótidos en el ARN copiado a partir de ADN que especifica el orden de
los aminoácidos en una proteína.
Las proteínas contienen 20 aminoácidos diferentes, pero el
DNA y el RNA contienen, cada uno, sólo cuatro nucleótidos diferentes. Si un solo
nucleótido "codificara" un aminoácido, entonces sólo cuatro aminoácidos podían
ser especificados por las cuatro bases nitrogenadas. Si dos nucleótidos
especificaran un aminoácido, entonces podría haber, usando todos los arreglos
posibles, un número máximo de 4 x 4, o sea 16 aminoácidos, lo cual es
insuficiente para codificar los veinte aminoácidos. Por lo tanto, por lo menos
tres nucleótidos en secuencia deben especificar cada aminoácido. Esto resulta en
4 x 4 x 4, o sea, 64 combinaciones posibles -los codones- lo cual,
claramente, es más que suficiente.
El código de tres nucleótidos, o código de tripletes, fue
ampliamente adoptado como hipótesis de trabajo. Sin embargo, su existencia no
fue realmente demostrada hasta que el código fue finalmente descifrado, una
década después que Watson y Crick presentaran por primera vez su modelo de la
estructura del DNA.
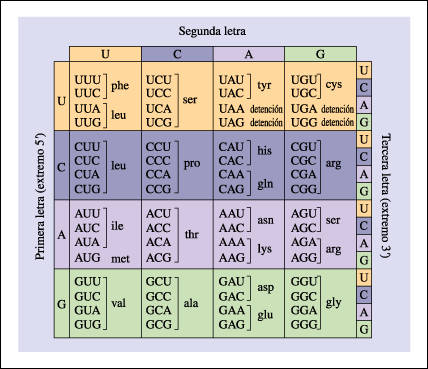
El código genético consiste en 64 combinaciones de tripletes
(codones) y sus aminoácidos correspondientes. Los codones que se muestran aquí
son los que puede presentar la molécula de mRNA. De los 64 codones, 6l
especifican aminoácidos particulares. Los otros 3 codones son señales de
detención, que determinan la finalización de la cadena. Dado que los 61
tripletes codifican para 20 aminoácidos, hay "sinónimos" como, por ejemplo, los
6 codones diferentes para la leucina.
La mayoría de los sinónimos, como se puede ver, difieren
solamente en el tercer nucleótido. Sin embargo, la afirmación inversa no es
válida: cada codón especifica solamente un aminoácido
|
El código genético consiste en 64 combinaciones de
tripletes (codones) y sus aminoácidos correspondientes.
|
 |
Fuente: Invitación a la Biología. H. Curtis.